Die letzten Monate führten zu einem Konstrukt, dass einige Vorteile bietet und sehr hilfreich in der Analytik von Fehlern oder Performanceeinschränkungen war und immer noch ist.
Wer mit VMware arbeitet weiss, dass auch hier ein solides Monitoring das A und O in der präventiven Fehlererkennung oder in der Nachbearbeitung von Ausfällen notwendig ist.
Nun, fast jedes System beinhaltet heute einen Dienst, der ständig mitteilen muss, was das System gerade macht, was ihm nicht passt, oder was es gerade versucht. Die Rede ist von Syslogs.
Aus alten VMware Zeiten kennt der eine oder andere sicher noch den Syslog Collector. Installiert auf einem Windowsserver, wurden alle Syslogmeldungen von den ESXi Servern in einfache Textdatei verfrachtet, mit einer Retention. Das wars dann aber auch. Zum durchforsten musste man sich dann anderen Tools bedienen.
Mit VMware LogInsight kam ein Produkt auf den Markt, dass die Daten nicht nur einfach in eine DB speichert, sondern auch visuell Darstellen konnte. Plötzlich waren es nicht nur kryptische Meldungen, Syslogdaten wurden grafisch und man konnte Verhalten anhand der Häufung der Meldungen erkennen, was dazu führte, dass man immer tiefer und tiefer in das Verhalten von einzelnen System werfen konnte. Syslog ist auch eines der Protokolle, welches noch dann Meldungen verschickt, wenn der Host schon längst keine Funktion mehr zeigt. Sprich man kann hier schon das letzte Husten des Hosts nutzen, um Meldungen und Reaktionen zu generieren.
Neben einer ganzen Zeile an bereits mitgelieferten Dashboards und Filtern kann man Log Insight auch für alle anderen Produkte nutzen, die Daten dahin zu schicken und eigene Dashboards erstellen oder man bedient sich an den vorhandenen Paketen im VMware Marketplace, die grösstenteils kostenlos zur Verfügung stehen.
Man kann nun auf einzelne Meldungen reagieren wie in einem bereits beschriebenen Beispiel, welche Meldung der HA Primary Host verschickt, sollte ein ESXi Host in einem HA Verbund Ausfallen und der Primary Host ihn dann für “Tod” erklärt. Mit ein paar weiteren Filtern kann man nun ganz einfach herausfinden, welche VMs ausgefallen sind und im Zuge von HA auf einem anderen Host neu gestartet werden.
Das ist alles schön, aber es geht noch eine Spur besser und gründlicher. Dafür reichen jedoch die Syslog Meldungen nicht mehr aus. Hier kommt VMware vRealize Operations Manager zum Zug. Dieser holt wichtige Daten in einem definierten Zeitabschnitt ab. Im Gegensatz zu Syslog, bei dem die Systeme diese realtime an Log Insight verschicken. Es ist auch möglich, via liagent Logfiles auf dem System zu lesen und deren Meldungen als Syslog an Log Insight zu verschicken.
Kleiner Einschub: Daraus erkennt man ein wenig heraus, warum man auf Syslog nicht verzichten soll. Das Produkt schreit förmlich danach, wenn es ein Problem hat und ein korrekt eingerichteter Alert wird auch realtime ausgelöst und nach entsprechenden Massnahmen erzwungen. vROps ist hier ein wenig träger, wenn man nicht mit EPOPs Agents oder zukünftig telegraph eingerichtet hat. Kommt immer auf den Fall und die Notwendigkeit an. Syslog bringt die Meldungen zum Log Insight, vROps holt die Meldungen von den Systemen ab.
Nun mit den erweiterten Daten, welche vROps sich holt, ist er auch in der Lage, ganz andere Sachen damit anzustellen. Er studiert täglich das Verhalten des Systems, erarbeitet Vorhersagen über Kapazitäten und Verbrauch. Er ist aber auch Grundlage für das Predictiv DRS. Sprich vROps versorgt das vCenter mit erweiterten Daten, damit z.B. Hosts pünktlich aus dem Standby nimmt, da vROps weiss, wann die User arbeiten und das System unter Last nehmen.
Da heute in vielen Bereichen mit Pods gearbeitet wird, stellt sich immer die Frage, wie richte ich nun das ganze ein, was ins sinnvoll. Hier möchte ich mal eine Variante vorstellen, die versucht, so viele Szenarien wie möglich abzudecken.
Wenn du dir jetzt erschlagen vorkommst, keine Sorge, wir schauen uns das nun Layer für Layer an, beginnen wir mit dem Pod Layer.
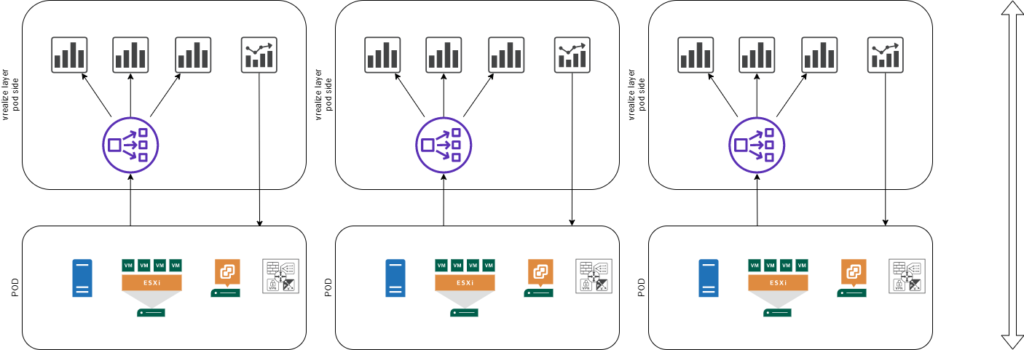
Der Pod Layer präsentiert ein wenig dass, wie das in den meisten Umgebungen der Fall ist. vCenter, ESXi, Server und vielleicht noch ein NSX-Manager oder ähnliches, sprich hier ist das ganze Ware verbaut, die für den Betrieb des Systems notwenig sind und die Verbraucher selber auch. Damit das überwacht werden kann, wird ein Syslog Collector verbaut und vielleicht auch eine vROps Primary Appliance.
In meinem Fall ist daran nicht viel anders, der Pod schickt seine Syslogdaten an einen normalen 3 Node Log Insight Cluster mit Loadbalancer. Hier werden Syslogdaten gespeichert, für die Langzeitaufbewahrung. In meinem Fall sind das aktuell 180 Tage. Was hier aber nicht eingerichtet wird, sind Alerts. Warum siehst du später. Anstatt einen vROps Cluster pro Pod zu erstellen, ist hier nur ein RemoteCollector verbaut. Hier ist jedoch die Möglichkeit offen, weitere Collector zu verbauen, sollte der eine mal die Last nicht mehr tragen können. Das ist aber aktuell mit ein paar Tausend VMs, NSX, Storages und Co. noch nie der Fall gewesen.
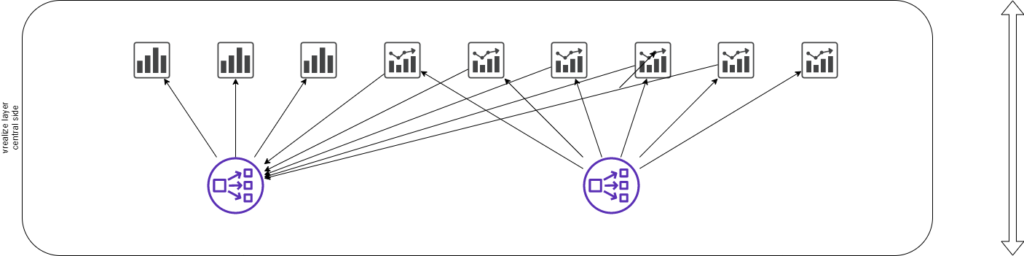
Nun kommen wir ein wenig zur Eigenheit des Designs. Hier ist erneut ein Log Insight Cluster mit 3 Nodes und Loadbalancer eingerichtet. Dieser hat aber nur noch eine Aufbewahrungszeit von 30 Tagen. Warum? Jede Log Insight Instanz hat einen Forwarder eingerichtet, damit die Daten aus dem Pod weiter an die Zentrale verschickt wird. Im Forwarder wird zusätzlich die Identifizierungstags für die environment, ob Produktiv, Test oder Integration, und ein Tag für den Podnamen oder -nummer. So kann später ausgewertet werden, ob z.B. ein Pod im Vergleich zu den anderen plötzlich mehr Daten verschickt als normal. Hier wird nun auch auf Muster reagiert und Alerts generiert, sprich man muss nicht auf jedem Pod eine Konfiguration vornehmen.
Das Konstrukt ist sehr hilfreich für die ersten Analyste von Problemen, sollte aber ein Muster gesucht werden, dass über die 30 Tage geht, hat man nun die Möglichkeit, explizit pro Pod in einem grösseren Datensatz suchen zu gehen.
Auf allen Syslog Appliances sind via Partitions die dfwlogs mit wesentlich kürzeren Retentions eingerichtet, pro Pod 14 Tage und zentral nur noch 2 Tage.
Auf diesem Layer befindet sich auch ein vROps Analytic Cluster mit einer Primären Appliances, einer Sekundären Appliance und 4 Datanodes. Alle Nodes sind mit einer zusätzlichen 250GB Disk ausgerüstet, da hier eine dermassen grosse Datenmenge anfällt. Bei gut 10’000 VMs ergbit das eine gute Auslastung von 60 – 70% von den verfügbaren 3 TB an Speicher, sprich hier sind doch seeehr viele Informationen gebunkert.
Die Verlinkung von vROps und vRLI passiert ebenfalls auf dieser Ebene, so kann man extrem schnell im Bedarfsfall den Workbench öffnen, anormales Verhalten erkennen und direkt in die Syslogs im entsprechenden Zeitfenster hineinblicken.
Sprich das ist alles eine sehr runde Sache, alle Informationen der letzten 30 Tage sind hier on Demand vorhanden. Die komplette Kapazitätsüberwachung kann gemacht werden und die Workloadplanung. Aber auch Compliances überwacht.
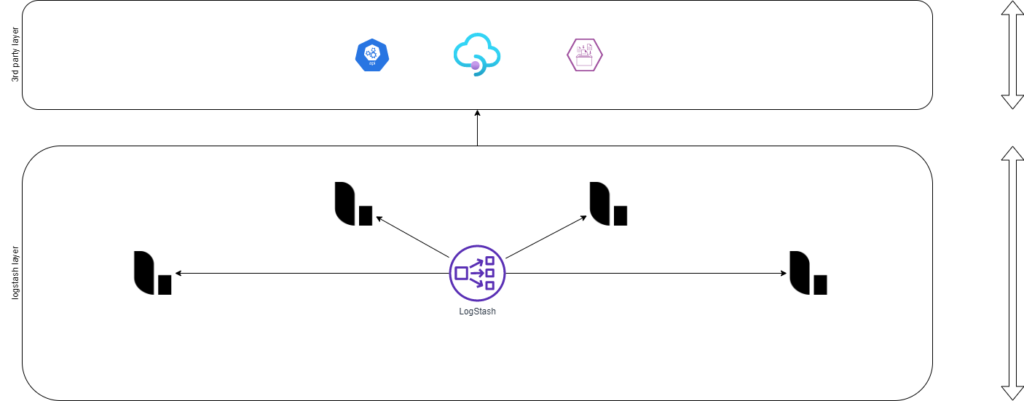
Die oberen Layer sind die beiden Zukunftsprojekte. Hier soll ein Logstash Cluster erstellt werden, der Daten aus der zentralen Seite empfangen soll und wo notwendig die Daten so abändern, damit diese z.B. auf ein Alarmsystem verschickt werden kann, bei dem das json vom vROps so angepasst werden muss, damit es für den Alarmdienst brauchbar wird. Oder Syslogdaten werden hier aus dem System geschleust und mit den notwendigen Tags versehen, welche z.B. auf einer noch zentraleren Ebene die Plattform identifiziert werden kann. Oder auch Mails verschickt oder eine andere API angeschubst werden kann. Sprich hier geht es in die Welt ausserhalb der Plattform.
Ein kleiner Blick auf die Security. Wenn wir die Sicht der Firewall einnehmen, haben wir eine recht einfache Übersicht, wer von wo nach wo Daten übertragen kann. Innerhalb des Pods können die Daten, je nach Subnetz einfach von den Systemen übermittelt oder abgeholt werden. In einem Mikrosegmentnetz sind natürlich entsprechend Regeln erforderlich.
Nun brauchen wir vom Pod Layer zum zentralen Layer eine Regel, damit Syslog die Daten an die zentrale Instanz schicken kann, einen Rückweg braucht es dazu nicht. Für vROps braucht es die Steuerports für den RemoteCollector und die Ports, damit die Daten an den Analytikcluster übertragen werden können. Aber auch hier ist das mit sehr wenig Regeln zu bewerkstelligen. So geht man kaum ein Risiko ein, dass man hier eine falsche Regel platziert und plötzlich von einem Pod in den anderen Kommuniziert werden kann.
Das mal als kleiner kurzer Abrieb, vielleicht für den einen oder anderen eine gute Lösung.